Marlos C. Machado
27 publications
13 venues
H Index 8
Affiliation
Department of Computing Science, University of Alberta, CanadaFederal University of Minas Gerais, Belo Horizonte, Brazil
Links
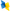


| Name | Venue | Year | citations |
|---|---|---|---|
Representation-driven Option Discovery in Reinforcement Learning.

|
AAAI | 2025 | 1 |
| Learning Continually by Spectral Regularization.
|
ICLR | 2025 | 0 |
| MaestroMotif: Skill Design from Artificial Intelligence Feedback.
|
ICLR | 2025 | 0 |
| Plastic Learning with Deep Fourier Features.
|
ICLR | 2025 | 0 |
| Averaging n-step Returns Reduces Variance in Reinforcement Learning.
|
ICML | 2024 | 7 |
| Reward-Respecting Subtasks for Model-Based Reinforcement Learning (Abstract Reprint).
|
AAAI | 2024 | 0 |
| Proper Laplacian Representation Learning.
|
ICLR | 2024 | 0 |
| GVFs in the real world: making predictions online for water treatment.
|
MLJ | 2024 | 0 |
| Investigating the properties of neural network representations in reinforcement learning.
|
Artificial Intelligence | 2024 | 0 |
| Trajectory-Aware Eligibility Traces for Off-Policy Reinforcement Learning.
|
ICML | 2023 | 4 |
| Deep Laplacian-based Options for Temporally-Extended Exploration.
|
ICML | 2023 | 31 |
| Temporal Abstraction in Reinforcement Learning with the Successor Representation.
|
JMLR | 2023 | 0 |
| Reward-respecting subtasks for model-based reinforcement learning.
|
Artificial Intelligence | 2023 | 0 |
| Temporal abstractions-augmented temporally contrastive learning: An alternative to the Laplacian in RL.
|
UAI | 2022 | 9 |
| A general class of surrogate functions for stable and efficient reinforcement learning.
|
AISTATS | 2022 | 0 |
| Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning.
|
ICLR | 2021 | 186 |
| Beyond Variance Reduction: Understanding the True Impact of Baselines on Policy Optimization.
|
ICML | 2021 | 0 |
| Exploration in Reinforcement Learning with Deep Covering Options.
|
ICLR | 2020 | 64 |
| An operator view of policy gradient methods.
|
NIPS/NeurIPS | 2020 | 28 |
| On Bonus Based Exploration Methods In The Arcade Learning Environment.
|
ICLR | 2020 | 72 |
| Count-Based Exploration with the Successor Representation.
|
AAAI | 2020 | 0 |
| Accelerating Learning in Constructive Predictive Frameworks with the Successor Representation.
|
IROS | 2018 | 10 |
| Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents (Extended Abstract).
|
IJCAI | 2018 | 8 |
| Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents.
|
JAIR | 2018 | 0 |
| A Laplacian Framework for Option Discovery in Reinforcement Learning.
|
ICML | 2017 | 281 |
| State of the Art Control of Atari Games Using Shallow Reinforcement Learning.
|
AAMAS | 2016 | 0 |
| True Online Temporal-Difference Learning.
|
JMLR | 2016 | 0 |