Bruno C. Da Silva 0001
34 publications
8 venues
H Index 15
Affiliation
University of Massachusetts, Amherst, MA, USAFederal University of Rio Grande do Sul (UFRGS), Institute of Informatics, Porto Alegre, Brazil
Links
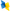

| Name | Venue | Year | citations |
|---|---|---|---|
Dynamic Option Creation in Option-Critic Reinforcement Learning.

|
AAMAS | 2025 | 1 |
| Position: Benchmarking is Limited in Reinforcement Learning Research.
|
ICML | 2024 | 14 |
| Abstract Reward Processes: Leveraging State Abstraction for Consistent Off-Policy Evaluation.
|
NIPS/NeurIPS | 2024 | 1 |
| From Past to Future: Rethinking Eligibility Traces.
|
AAAI | 2024 | 0 |
| Sample-Efficient Multi-Objective Learning via Generalized Policy Improvement Prioritization.
|
AAMAS | 2023 | 52 |
| A Toolkit for Reliable Benchmarking and Research in Multi-Objective Reinforcement Learning.
|
NIPS/NeurIPS | 2023 | 1 |
| Behavior Alignment via Reward Function Optimization.
|
NIPS/NeurIPS | 2023 | 20 |
| Multi-Step Generalized Policy Improvement by Leveraging Approximate Models.
|
NIPS/NeurIPS | 2023 | 4 |
| Fairness Guarantees under Demographic Shift.
|
ICLR | 2022 | 55 |
| Optimistic Linear Support and Successor Features as a Basis for Optimal Policy Transfer.
|
ICML | 2022 | 34 |
| Constrained Offline Policy Optimization.
|
ICML | 2022 | 17 |
| Off-Policy Evaluation for Action-Dependent Non-stationary Environments.
|
NIPS/NeurIPS | 2022 | 0 |
| Universal Off-Policy Evaluation.
|
NIPS/NeurIPS | 2021 | 58 |
| Posterior Value Functions: Hindsight Baselines for Policy Gradient Methods.
|
ICML | 2021 | 6 |
| Minimum-Delay Adaptation in Non-Stationary Reinforcement Learning via Online High-Confidence Change-Point Detection.
|
AAMAS | 2021 | 27 |
| A Methodology for Neural Network Architectural Tuning Using Activation Occurrence Maps.
|
IJCNN | 2019 | 6 |
| A Compression-Inspired Framework for Macro Discovery.
|
AAMAS | 2019 | 0 |
| Towards Designing Optimal Reward Functions in Multi-Agent Reinforcement Learning Problems.
|
IJCNN | 2018 | 8 |
| Comparing Multi-Armed Bandit Algorithms and Q-learning for Multiagent Action Selection: a Case Study in Route Choice.
|
IJCNN | 2018 | 18 |
| Context-Based Concurrent Experience Sharing in Multiagent Systems.
|
AAMAS | 2017 | 3 |
| A Flexible Approach for Designing Optimal Reward Functions.
|
AAMAS | 2017 | 9 |
| Learning to Minimise Regret in Route Choice.
|
AAMAS | 2017 | 19 |
| Task-based behavior generalization via manifold clustering.
|
IROS | 2017 | 2 |
| Energetic Natural Gradient Descent.
|
ICML | 2016 | 22 |
| Learning parameterized motor skills on a humanoid robot.
|
ICRA | 2014 | 51 |
| Active Learning of Parameterized Skills.
|
ICML | 2014 | 30 |
| Biasing the behavior of organizationally adept agents: (extended abstract).
|
AAMAS | 2013 | 3 |
| Learning Parameterized Skills.
|
ICML | 2012 | 211 |
| TD-DeltaPi: A Model-Free Algorithm for Efficient Exploration.
|
AAAI | 2012 | 0 |
| Distributed constraint propagation for diagnosis of faults in physical processes.
|
AAMAS | 2007 | 2 |
| Improving reinforcement learning with context detection.
|
AAMAS | 2006 | 25 |
| RL-CD: Dealing with Non-Stationarity in Reinforcement Learning.
|
AAAI | 2006 | 1 |
| Dealing with non-stationary environments using context detection.
|
ICML | 2006 | 199 |
| ITSUMO: an Intelligent Transportation System for Urban Mobility.
|
AAMAS | 2006 | 0 |